Başlatıcı kısa bir DNA dizisidir (ökaryotta TATAAA ya da TATA kutusu).
RNA polimeraz DNAnın çift sarmalını ayırır ve uzatma sırasında mRNA kalıp bir DNA telini (antisense strand) 3' → 5' yönünde okurken büyümekte olan mRNA teline 5' → 3' yönünde nükleotidler ekler.
Sonlandırma evresinde RNA polimeraz ve mRNA teli DNA kalıp telinden ayrılır.
Gen anlatımı:
DnA → RnA → protein.
Bir ökariotik hücrede çekirdekteki DNA iletmen RNAnın (mRNA) bireşimini sağlayarak sitoplazmada protein üretimini planlar.
Her hücre her geni kapsar.
Aynı genetik bilgiyi taşıyan hücreler yapı ve işlevde özelleşir ve belli genleri etkinleştiren denetim düzenekleri yoluyla ayrı hücre tiplerine gelişir (nöron, alyuvar vb.).
Genler belirli mRNA moleküllerinin nükleotid dizisini belirler.
Kendi payına mRNA proteinlerdeki amino asit dizisini belirler.
DNA → RNA → protein.
Etkinleştirilen bir gen mRNA olarak üretilir (eşyazım) ve bu mesaj belirli proteinlere çevrilir (çeviri).
Bütün süreç ‘gen anlatımı’dır.
📹📹📹 GENE EXPRESSION (VİDEO)
📹 Transcription and Translation — Protein Synthesis From DNA / The Organic Chemistry Tutor (VİDEO)
📹 Transcription and Translation / The Organic Chemistry Tutor (LINK)
This biology video tutorial provides a basic introduction into transcription and translation which explains protein synthesis starting from DNA. Transcription is the process where DNA is used to create mRNA. RNA polymerase constructs DNA using the template strand or antisense strand. The other strand is called the noncoding strand or nontemplate strand. pre-mRNA is actually created first through 3 processes - initiation, elongation, and termination. After which, pre-mRNA undergoes RNA splicing where the introns are removed and the exons remain. mRNA now leaves the nucleus and enters the cytosol where it finds a ribosome which is the site where proteins are made. The nucleotide sequence found in mRNA is broken into sets of 3 forming codons which matches the anticodons found in tRNA. The transfer RNA molecule brings the amino acids needed to make the growing polypeptide chain forming a protein. The ribosome has three sites - The E site or exit site, the P site or peptidyl site, and the A site or amino acyl site where most tRNA molecules enter.
📹 Transcription and mRNA processing / Khan Academy (VİDEO)
📹 Transcription and mRNA processing / Khan Academy (LINK)
Introduction to transcription including the role of RNA polymerase, promoters, terminators, introns and exons.
📹 Translation (mRNA to protein) / Khan Academy (VİDEO)
📹 Translation (mRNA to protein) / Khan Academy (LINK)
A deep dive into how mRNA is translated into proteins with the help of ribosomes and tRNA.
In genetics,gene expression is the most fundamental level at which the genotype gives rise to the phenotype,i.e. observable trait. The genetic information stored in DNA represents the genotype, whereas the phenotype results from the "interpretation" of that information. Such phenotypes are often expressed by the synthesis of proteins that control the organism's structure and development, or that act as enzymes catalyzing specific metabolic pathways.
The production of a RNA copy from a DNA strand is called transcription, and is performed by RNA polymerases, which add one ribonucleotide at a time to a growing RNA strand as per the complementarity law of the nucleotide bases. This RNA is complementary to the template 3' → 5' DNA strand, with the exception that thymines (T) are replaced with uracils (U) in the RNA.
In prokaryotes, transcription is carried out by a single type of RNA polymerase, which needs to bind a DNA sequence called a Pribnow box with the help of the sigma factor protein (σ factor) to start transcription. In eukaryotes, transcription is performed in the nucleus by three types of RNA polymerases, each of which needs a special DNA sequence called the promoter and a set of DNA-binding proteins — transcription factors — to initiate the process (see regulation of transcription below). RNA polymerase I is responsible for transcription of ribosomal RNA (rRNA) genes. RNA polymerase II (Pol II) transcribes all protein-coding genes but also some non-coding RNAs (e.g., snRNAs, snoRNAs or long non-coding RNAs). RNA polymerase III transcribes 5S rRNA, transfer RNA (tRNA) genes, and some small non-coding RNAs (e.g., 7SK). Transcription ends when the polymerase encounters a sequence called the terminator.
The process of transcription is carried out by RNA polymerase (RNAP), which uses DNA (black) as a template and produces RNA (blue).
While transcription of prokaryotic protein-coding genes creates messenger RNA (mRNA) that is ready for translation into protein, transcription of eukaryotic genes leaves a primary transcript of RNA (pre-RNA), which first has to undergo a series of modifications to become a mature RNA. Types and steps involved in the maturation processes vary between coding and non-coding preRNAs; i.e. even though preRNA molecules for both mRNA and tRNA undergo splicing, the steps and machinery involved are different. The processing of non-coding RNA is described below (non-coring RNA maturation).
The processing of premRNA include 5' capping, which is set of enzymatic reactions that add 7-methylguanosine (m7G) to the 5' end of pre-mRNA and thus protect the RNA from degradation by exonucleases. The m7G cap is then bound by cap binding complex heterodimer (CBC20/CBC80), which aids in mRNA export to cytoplasm and also protect the RNA from decapping.
Another modification is 3' cleavage and polyadenylation. They occur if polyadenylation signal sequence (5'- AAUAAA-3') is present in pre-mRNA, which is usually between protein-coding sequence and terminator. The pre-mRNA is first cleaved and then a series of ~200 adenines (A) are added to form poly(A) tail, which protects the RNA from degradation. The poly(A) tail is bound by multiple poly(A)-binding proteins (PABPs) necessary for mRNA export and translation re-initiation. In the inverse process of deadenylation, poly(A) tails are shortened by the CCR4-Not 3′-5′ exonuclease, which often leads to full transcript decay.
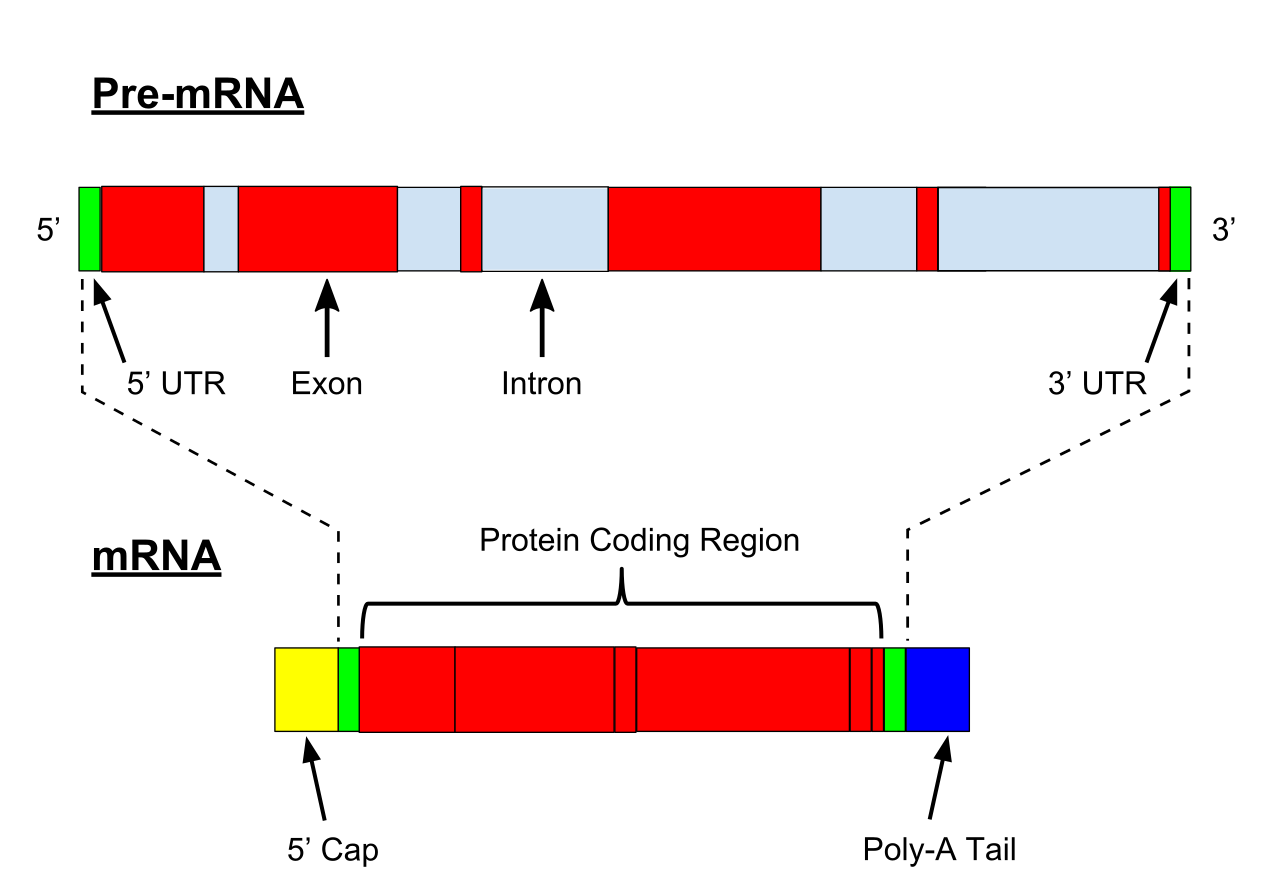
A very important modification of eukaryotic pre-mRNA is RNA splicing. The majority of eukaryotic pre-mRNAs consist of alternating segments called exons and introns. During the process of splicing, an RNA-protein catalytical complex known as spliceosome catalyzes two transesterification reactions, which remove an intron and release it in form of lariat structure, and then splice neighbouring exons together. In certain cases, some introns or exons can be either removed or retained in mature mRNA. This so-called alternative splicing creates series of different transcripts originating from a single gene. Because these transcripts can be potentially translated into different proteins, splicing extends the complexity of eukaryotic gene expression and the size of a species proteome.
Extensive RNA processing may be an evolutionary advantage made possible by the nucleus of eukaryotes. In prokaryotes, transcription and translation happen together, whilst in eukaryotes, the nuclear membrane separates the two processes, giving time for RNA processing to occur.
Illustration of exons and introns in pre-mRNA and the formation of mature mRNA by splicing. The UTRs (in green) are non-coding parts of exons at the ends of the mRNA.
In most organisms non-coding genes (ncRNA) are transcribed as precursors that undergo further processing. In the case of ribosomal RNAs (rRNA), they are often transcribed as a pre-rRNA that contains one or more rRNAs. The pre-rRNA is cleaved and modified (2′-O-methylation and pseudouridine formation) at specific sites by approximately 150 different small nucleolus-restricted RNA species, called snoRNAs. SnoRNAs associate with proteins, forming snoRNPs. While snoRNA part basepair with the target RNA and thus position the modification at a precise site, the protein part performs the catalytical reaction. In eukaryotes, in particular a snoRNP called RNase, MRP cleaves the 45S pre-rRNA into the 28S, 5.8S, and 18S rRNAs. The rRNA and RNA processing factors form large aggregates called the nucleolus.
In the case of transfer RNA (tRNA), for example, the 5' sequence is removed by RNase P, whereas the 3' end is removed by the tRNase Z enzyme and the non-templated 3' CCA tail is added by a nucleotidyl transferase. In the case of micro RNA (miRNA), miRNAs are first transcribed as primary transcripts or pri-miRNA with a cap and poly-A tail and processed to short, 70-nucleotide stem-loop structures known as pre-miRNA in the cell nucleus by the enzymes Drosha and Pasha. After being exported, it is then processed to mature miRNAs in the cytoplasm by interaction with the endonuclease Dicer, which also initiates the formation of the RNA-induced silencing complex (RISC), composed of the Argonaute protein.
Even snRNAs and snoRNAs themselves undergo series of modification before they become part of functional RNP complex. This is done either in the nucleoplasm or in the specialized compartments called Cajal bodies. Their bases are methylated or pseudouridinilated by a group of small Cajal body-specific RNAs (scaRNAs), which are structurally similar to snoRNAs.
In eukaryotes most mature RNA must be exported to the cytoplasm from the nucleus. While some RNAs function in the nucleus, many RNAs are transported through the nuclear pores and into the cytosol. Export of RNAs requires association with specific proteins known as exportins. Specific exportin molecules are responsible for the export of a given RNA type. mRNA transport also requires the correct association with Exon Junction Complex (EJC), which ensures that correct processing of the mRNA is completed before export. In some cases RNAs are additionally transported to a specific part of the cytoplasm, such as a synapse; they are then towed by motor proteins that bind through linker proteins to specific sequences (called "zipcodes") on the RNA.
For some RNA (non-coding RNA) the mature RNA is the final gene product. In the case of messenger RNA (mRNA) the RNA is an information carrier coding for the synthesis of one or more proteins. mRNA carrying a single protein sequence (common in eukaryotes) is monocistronic whilst mRNA carrying multiple protein sequences (common in prokaryotes) is known as polycistronic.
Every mRNA consists of three parts: a 5' untranslated region (5'UTR), a protein-coding region or open reading frame (ORF), and a 3' untranslated region (3'UTR). The coding region carries information for protein synthesis encoded by the genetic code to form triplets. Each triplet of nucleotides of the coding region is called a codon and corresponds to a binding site complementary to an anticodon triplet in transfer RNA. Transfer RNAs with the same anticodon sequence always carry an identical type of amino acid. Amino acids are then chained together by the ribosome according to the order of triplets in the coding region. The ribosome helps transfer RNA to bind to messenger RNA and takes the amino acid from each transfer RNA and makes a structure-less protein out of it. Each mRNA molecule is translated into many protein molecules, on average ~2800 in mammals.
In prokaryotes translation generally occurs at the point of transcription (co-transcriptionally), often using a messenger RNA that is still in the process of being created. In eukaryotes translation can occur in a variety of regions of the cell depending on where the protein being written is supposed to be. Major locations are the cytoplasm for soluble cytoplasmic proteins and the membrane of the endoplasmic reticulum for proteins that are for export from the cell or insertion into a cell membrane. Proteins that are supposed to be expressed at the endoplasmic reticulum are recognised part-way through the translation process. This is governed by the signal recognition particle—a protein that binds to the ribosome and directs it to the endoplasmic reticulum when it finds a signal peptide on the growing (nascent) amino acid chain.
During the translation, tRNA charged with amino acid enters the ribosome and aligns with the correct mRNA triplet. Ribosome then adds amino acid to growing protein chain.
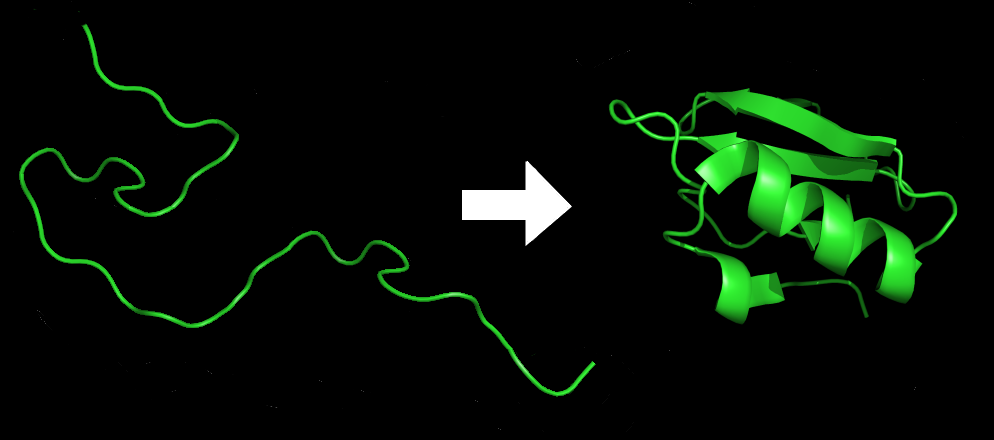
Each protein exists as an unfolded polypeptide or random coil when translated from a sequence of mRNA into a linear chain of amino acids. This polypeptide lacks any developed three-dimensional structure (the left hand side of the neighboring figure). The polypeptide then folds into its characteristic and functional three-dimensional structure from a random coil. Amino acids interact with each other to produce a well-defined three-dimensional structure, the folded protein (the right hand side of the figure) known as the native state. The resulting three-dimensional structure is determined by the amino acid sequence (Anfinsen's dogma).
The correct three-dimensional structure is essential to function, although some parts of functional proteins may remain unfolded. Failure to fold into the intended shape usually produces inactive proteins with different properties including toxic prions. Several neurodegenerative and other diseases are believed to result from the accumulation of misfolded proteins. Many allergies are caused by the folding of the proteins, for the immune system does not produce antibodies for certain protein structures.
Enzymes called chaperones assist the newly formed protein to attain (fold into) the 3-dimensional structure it needs to function. Similarly, RNA chaperones help RNAs attain their functional shapes. Assisting protein folding is one of the main roles of the endoplasmic reticulum in eukaryotes.
Secretory proteins of eukaryotes or prokaryotes must be translocated to enter the secretory pathway. Newly synthesized proteins are directed to the eukaryotic Sec61 or prokaryotic SecYEG translocation channel by signal peptides. The efficiency of protein secretion in eukaryotes is very dependent on the signal peptide which has been used.
Many proteins are destined for other parts of the cell than the cytosol and a wide range of signalling sequences or (signal peptides) are used to direct proteins to where they are supposed to be. In prokaryotes this is normally a simple process due to limited compartmentalisation of the cell. However, in eukaryotes there is a great variety of different targeting processes to ensure the protein arrives at the correct organelle.
Not all proteins remain within the cell and many are exported, for example, digestive enzymes,hormones and extracellular matrix proteins. In eukaryotes the export pathway is well developed and the main mechanism for the export of these proteins is translocation to the endoplasmic reticulum, followed by transport via the Golgi apparatus.
Regulation of gene expression refers to the control of the amount and timing of appearance of the functional product of a gene. Control of expression is vital to allow a cell to produce the gene products it needs when it needs them; in turn, this gives cells the flexibility to adapt to a variable environment, external signals, damage to the cell, and other stimuli. More generally, gene regulation gives the cell control over all structure and function, and is the basis for cellular differentiation,morphogenesis and the versatility and adaptability of any organism.
Numerous terms are used to describe types of genes depending on how they are regulated; these include:
A constitutive gene is a gene that is transcribed continually as opposed to a facultative gene, which is only transcribed when needed.
A housekeeping gene is a gene that is required to maintain basic cellular function and so is typically expressed in all cell types of an organism. Examples include actin,GAPDH and ubiquitin. Some housekeeping genes are transcribed at a relatively constant rate and these genes can be used as a reference point in experiments to measure the expression rates of other genes.
A facultative gene is a gene only transcribed when needed as opposed to a constitutive gene.
An inducible gene is a gene whose expression is either responsive to environmental change or dependent on the position in the cell cycle.
Any step of gene expression may be modulated, from the DNA-RNA transcription step to post-translational modification of a protein. The stability of the final gene product, whether it is RNA or protein, also contributes to the expression level of the gene—an unstable product results in a low expression level. In general gene expression is regulated through changes in the number and type of interactions between molecules that collectively influence transcription of DNA and translation of RNA.
Some simple examples of where gene expression is important are:
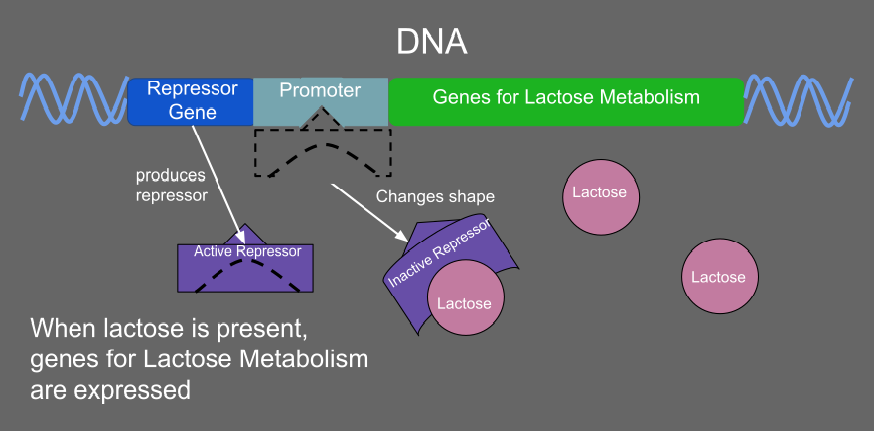
When lactose is present in a prokaryote, it acts as an inducer and inactivates the repressor so that the genes for lactose metabolism can be transcribed.
Regulation of transcription can be broken down into three main routes of influence; genetic (direct interaction of a control factor with the gene), modulation interaction of a control factor with the transcription machinery and epigenetic (non-sequence changes in DNA structure that influence transcription).
Direct interaction with DNA is the simplest and the most direct method by which a protein changes transcription levels. Genes often have several protein binding sites around the coding region with the specific function of regulating transcription. There are many classes of regulatory DNA binding sites known as enhancers,insulators and silencers. The mechanisms for regulating transcription are very varied, from blocking key binding sites on the DNA for RNA polymerase to acting as an activator and promoting transcription by assisting RNA polymerase binding.
The activity of transcription factors is further modulated by intracellular signals causing protein post-translational modification including phosphorylated,acetylated, or glycosylated. These changes influence a transcription factor's ability to bind, directly or indirectly, to promoter DNA, to recruit RNA polymerase, or to favor elongation of a newly synthesized RNA molecule.
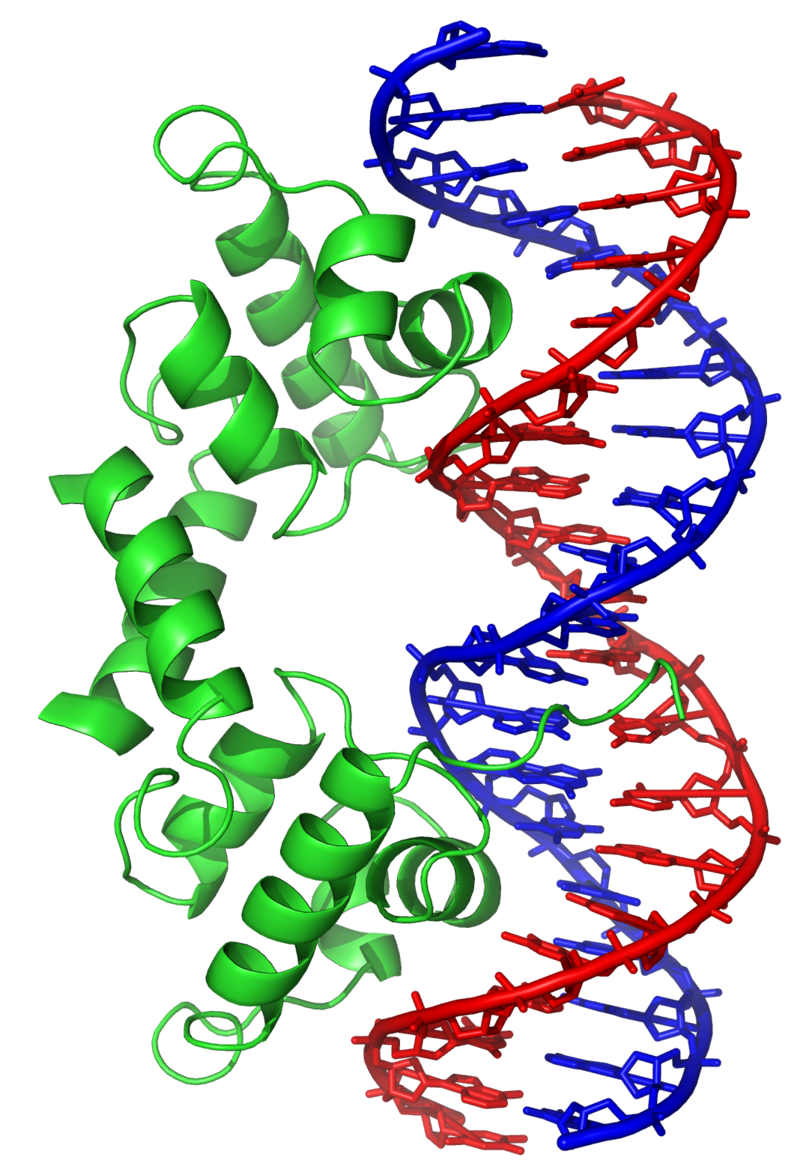
The lambda repressor transcription factor (green) binds as a dimer to major groove of DNA target (red and blue) and disables initiation of transcription. From PDB:1LMB.
The nuclear membrane in eukaryotes allows further regulation of transcription factors by the duration of their presence in the nucleus, which is regulated by reversible changes in their structure and by binding of other proteins. Environmental stimuli or endocrine signals may cause modification of regulatory proteins eliciting cascades of intracellular signals, which result in regulation of gene expression.
More recently it has become apparent that there is a significant influence of non-DNA-sequence specific effects on transcription. These effects are referred to as epigenetic and involve the higher order structure of DNA, non-sequence specific DNA binding proteins and chemical modification of DNA. In general epigenetic effects alter the accessibility of DNA to proteins and so modulate transcription.
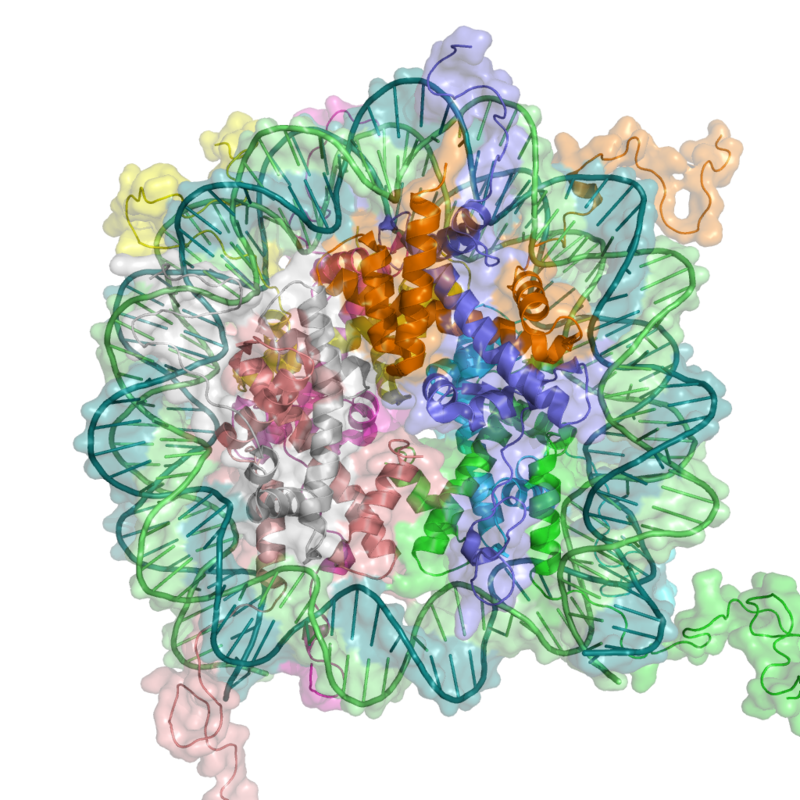
In eukaryotes, DNA is organized in form of nucleosomes. Note how the DNA (blue and green) is tightly wrapped around the protein core made of histoneoctamer (ribbon coils), restricting access to the DNA. From PDB:1KX5.
DNA methylation and demethylation in transcriptional regulation
DNA methylation and demethylation in transcriptional regulation (W)
DNA methylation is the addition of a methyl group to the DNA that happens at cytosine. The image shows a cytosine single ring base and a methyl group added on to the 5 carbon. In mammals, DNA methylation occurs almost exclusively at a cytosine that is followed by a guanine.
DNA methylation is a widespread mechanism for epigenetic influence on gene expression and is seen in bacteria and eukaryotes and has roles in heritable transcription silencing and transcription regulation. Methylation most often occurs on a cytosine (see Figure). Methylation of cytosine primarily occurs in dinucleotide sequences where a cytosine is followed by a guanine, a CpG site. The number of CpG sites in the human genome is about 28 million. Depending on the type of cell, about 70% of the CpG sites have a methylated cytosine.
Methylation of cytosine in DNA has a major role in regulating gene expression. Methylation of CpGs in a promoter region of a gene usually represses gene transcription while methylation of CpGs in the body of a gene increases expression. TET enzymes play a central role in demethylation of methylated cytosines. Demethylation of CpGs in a gene promoter by TET enzyme activity increases transcription of the gene.
Transcriptional regulation in learning and memory
Transcriptional regulation in learning and memory (W)
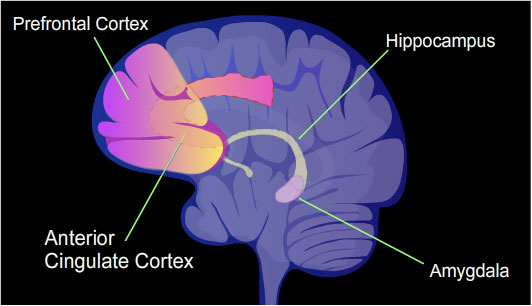
The identified areas of the human brain are involved in memory formation.
In a rat, contextual fear conditioning (CFC) is a painful learning experience. Just one episode of CFC can result in a life-long fearful memory. After an episode of CFC, cytosine methylation is altered in the promoter regions of about 9.17% of all genes in the hippocampus neuron DNA of a rat. The hippocampus is where new memories are initially stored. After CFC about 500 genes have increased transcription (often due to demethylation of CpG sites in a promoter region) and about 1,000 genes have decreased transcription (often due to newly formed 5-methylcytosine at CpG sites in a promoter region). The pattern of induced and repressed genes within neurons appears to provide a molecular basis for forming the first transient memory of this training event in the hippocampus of the rat brain.
In particular, the brain-derived neurotrophic factor gene (BDNF) is known as a "learning gene." After CFC there was upregulation of BDNF gene expression, related to decreased CpG methylation of certain internal promoters of the gene, and this was correlated with learning.
The majority of gene promoters contain a CpG island with numerous CpG sites. When many of a gene's promoter CpG sites are methylated the gene becomes silenced. Colorectal cancers typically have 3 to 6 driver mutations and 33 to 66 hitchhiker or passenger mutations. However, transcriptional silencing may be of more importance than mutation in causing progression to cancer. For example, in colorectal cancers about 600 to 800 genes are transcriptionally silenced by CpG island methylation (see regulation of transcription in cancer). Transcriptional repression in cancer can also occur by other epigenetic mechanisms, such as altered expression of microRNAs. In breast cancer, transcriptional repression of BRCA1 may occur more frequently by over-expressed microRNA-182 than by hypermethylation of the BRCA1 promoter (see Low expression of BRCA1 in breast and ovarian cancers).
In eukaryotes, where export of RNA is required before translation is possible, nuclear export is thought to provide additional control over gene expression. All transport in and out of the nucleus is via the nuclear pore and transport is controlled by a wide range of importin and exportin proteins.
Expression of a gene coding for a protein is only possible if the messenger RNA carrying the code survives long enough to be translated. In a typical cell, an RNA molecule is only stable if specifically protected from degradation. RNA degradation has particular importance in regulation of expression in eukaryotic cells where mRNA has to travel significant distances before being translated. In eukaryotes, RNA is stabilised by certain post-transcriptional modifications, particularly the 5' cap and poly-adenylated tail.
Intentional degradation of mRNA is used not just as a defence mechanism from foreign RNA (normally from viruses) but also as a route of mRNA destabilisation. If an mRNA molecule has a complementary sequence to a small interfering RNA then it is targeted for destruction via the RNA interference pathway.
Three prime untranslated regions and microRNAs
Three prime untranslated regions and microRNAs (W)
Three prime untranslated regions (3'UTRs) of messenger RNAs (mRNAs) often contain regulatory sequences that post-transcriptionally influence gene expression. Such 3'-UTRs often contain both binding sites for microRNAs (miRNAs) as well as for regulatory proteins. By binding to specific sites within the 3'-UTR, miRNAs can decrease gene expression of various mRNAs by either inhibiting translation or directly causing degradation of the transcript. The 3'-UTR also may have silencer regions that bind repressor proteins that inhibit the expression of a mRNA.
The 3'-UTR often contains microRNA response elements (MREs). MREs are sequences to which miRNAs bind. These are prevalent motifs within 3'-UTRs. Among all regulatory motifs within the 3'-UTRs (e.g. including silencer regions), MREs make up about half of the motifs.
As of 2014, the miRBase web site, an archive of miRNAsequences and annotations, listed 28,645 entries in 233 biologic species. Of these, 1,881 miRNAs were in annotated human miRNA loci. miRNAs were predicted to have an average of about four hundred target mRNAs (affecting expression of several hundred genes). Friedman et al. estimate that >45,000 miRNA target sites within human mRNA 3'UTRs are conserved above background levels, and >60% of human protein-coding genes have been under selective pressure to maintain pairing to miRNAs.
Direct experiments show that a single miRNA can reduce the stability of hundreds of unique mRNAs. Other experiments show that a single miRNA may repress the production of hundreds of proteins, but that this repression often is relatively mild (less than 2-fold).
The effects of miRNA dysregulation of gene expression seem to be important in cancer. For instance, in gastrointestinal cancers, nine miRNAs have been identified as epigenetically altered and effective in down regulating DNA repair enzymes.
The effects of miRNA dysregulation of gene expression also seem to be important in neuropsychiatric disorders, such as schizophrenia, bipolar disorder, major depression, Parkinson's disease, Alzheimer's disease and autism spectrum disorders.
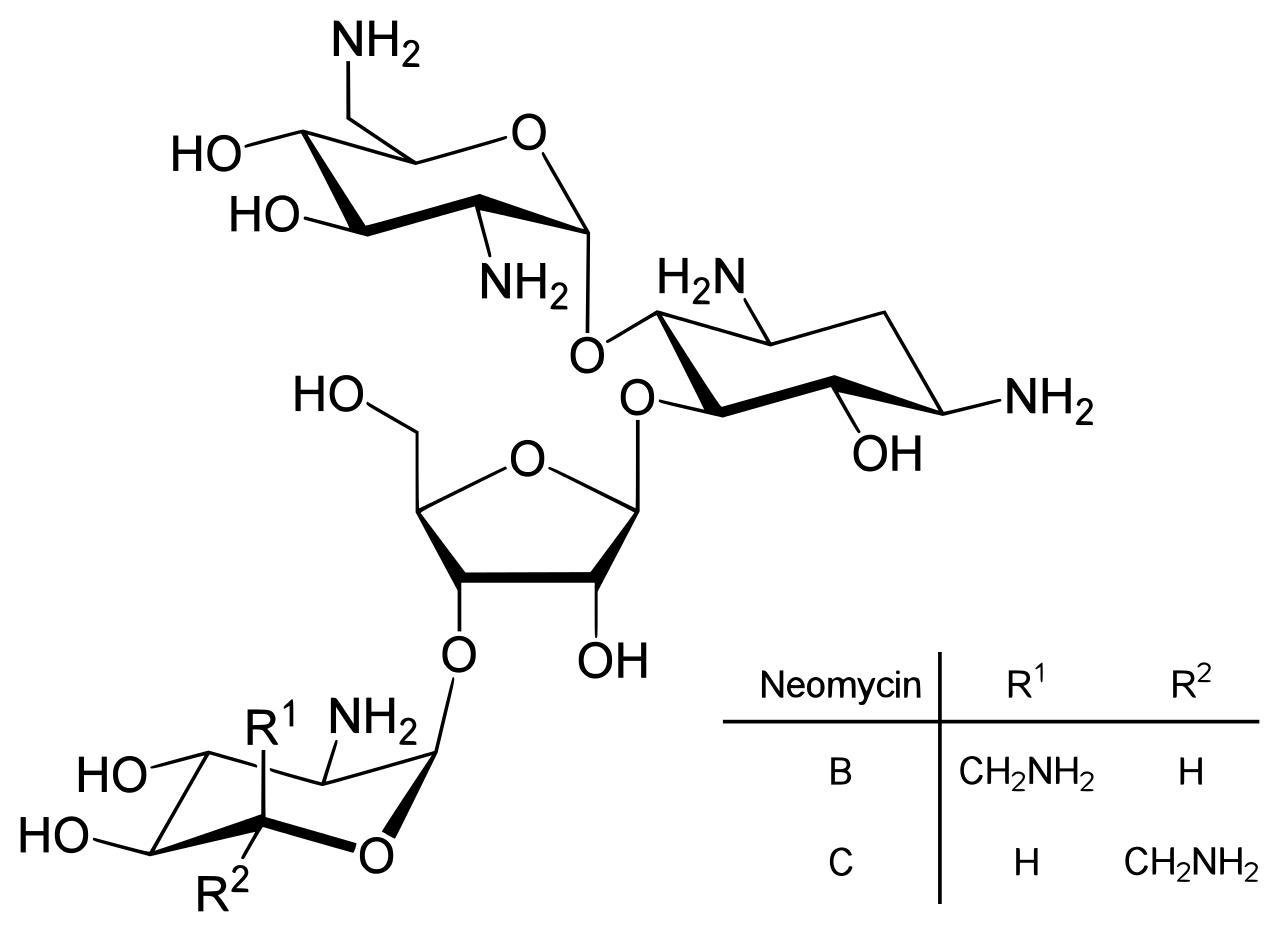
Neomycin is an example of a small molecule that reduces expression of all protein genes inevitably leading to cell death; it thus acts as an antibiotic.
Direct regulation of translation is less prevalent than control of transcription or mRNA stability but is occasionally used. Inhibition of protein translation is a major target for toxins and antibiotics, so they can kill a cell by overriding its normal gene expression control. Protein synthesis inhibitors include the antibiotic neomycin and the toxin ricin.
Post-translational modifications (PTMs) are covalent modifications to proteins. Like RNA splicing, they help to significantly diversify the proteome. These modifications are usually catalyzed by enzymes. Additionally, processes like covalent additions to amino acid side chain residues can often be reversed by other enzymes. However, some, like the proteolytic cleavage of the protein backbone, are irreversible.
PTMs play many important roles in the cell.For example, phosphorylation is primarily involved in activating and deactivating proteins and in signaling pathways.PTMs are involved in transcriptional regulation: an important function of acetylation and methylation is histone tail modification, which alters how accessible DNA is for transcription. They can also be seen in the immune system, where glycosylation plays a key role.One type of PTM can initiate another type of PTM, as can be seen in how ubiquitination tags proteins for degradation through proteolysis.Proteolysis, other than being involved in breaking down proteins, is also important in activating and deactivating them, and in regulating biological processes such as DNA transcription and cell death.
Measuring gene expression is an important part of many life sciences, as the ability to quantify the level at which a particular gene is expressed within a cell, tissue or organism can provide a lot of valuable information. For example, measuring gene expression can:
Identify viral infection of a cell (viral protein expression).
Determine an individual's susceptibility to cancer (oncogene expression).
Similarly, the analysis of the location of protein expression is a powerful tool, and this can be done on an organismal or cellular scale. Investigation of localization is particularly important for the study of development in multicellular organisms and as an indicator of protein function in single cells. Ideally, measurement of expression is done by detecting the final gene product (for many genes, this is the protein); however, it is often easier to detect one of the precursors, typically mRNA and to infer gene-expression levels from these measurements.
Levels of mRNA can be quantitatively measured by northern blotting, which provides size and sequence information about the mRNA molecules. A sample of RNA is separated on an agarose gel and hybridized to a radioactively labeled RNA probe that is complementary to the target sequence. The radiolabeled RNA is then detected by an autoradiograph. Because the use of radioactive reagents makes the procedure time consuming and potentially dangerous, alternative labeling and detection methods, such as digoxigenin and biotin chemistries, have been developed. Perceived disadvantages of Northern blotting are that large quantities of RNA are required and that quantification may not be completely accurate, as it involves measuring band strength in an image of a gel. On the other hand, the additional mRNA size information from the Northern blot allows the discrimination of alternately spliced transcripts.
Another approach for measuring mRNA abundance is RT-qPCR. In this technique, reverse transcription is followed by quantitative PCR. Reverse transcription first generates a DNA template from the mRNA; this single-stranded template is called cDNA. The cDNA template is then amplified in the quantitative step, during which the fluorescence emitted by labeled hybridization probes or intercalating dyes changes as the DNA amplification process progresses. With a carefully constructed standard curve, qPCR can produce an absolute measurement of the number of copies of original mRNA, typically in units of copies per nanolitre of homogenized tissue or copies per cell. qPCR is very sensitive (detection of a single mRNA molecule is theoretically possible), but can be expensive depending on the type of reporter used; fluorescently labeled oligonucleotide probes are more expensive than non-specific intercalating fluorescent dyes.
For expression profiling, or high-throughput analysis of many genes within a sample, quantitative PCR may be performed for hundreds of genes simultaneously in the case of low-density arrays. A second approach is the hybridization microarray. A single array or "chip" may contain probes to determine transcript levels for every known gene in the genome of one or more organisms. Alternatively, "tag based" technologies like Serial analysis of gene expression (SAGE) and RNA-Seq, which can provide a relative measure of the cellular concentration of different mRNAs, can be used. An advantage of tag-based methods is the "open architecture", allowing for the exact measurement of any transcript, with a known or unknown sequence. Next-generation sequencing (NGS) such as RNA-Seq is another approach, producing vast quantities of sequence data that can be matched to a reference genome. Although NGS is comparatively time-consuming, expensive, and resource-intensive, it can identify single-nucleotide polymorphisms, splice-variants, and novel genes, and can also be used to profile expression in organisms for which little or no sequence information is available.
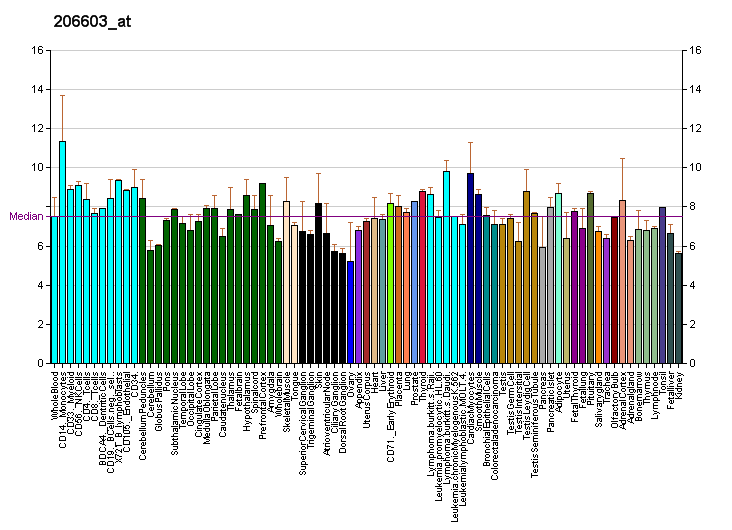
Profiles like these are found for almost all proteins listed in Wikipedia. They are generated by organizations such as the Genomics Institute of the Novartis Research Foundation and the European Bioinformatics Institute. Additional information can be found by searching their databases (for an example of the GLUT4 transporter pictured here, see citation). These profiles indicate the level of DNA expression (and hence RNA produced) of a certain protein in a certain tissue, and are color-coded accordingly in the images located in the Protein Box on the right side of each Wikipedia page.
The RNA expression profile of the GLUT4 Transporter (one of the main glucose transporters found in the human body).
For genes encoding proteins, the expression level can be directly assessed by a number of methods with some clear analogies to the techniques for mRNA quantification.
The most commonly used method is to perform a Western blot against the protein of interest—this gives information on the size of the protein in addition to its identity. A sample (often cellular lysate) is separated on a polyacrylamide gel, transferred to a membrane and then probed with an antibody to the protein of interest. The antibody can either be conjugated to a fluorophore or to horseradish peroxidase for imaging and/or quantification. The gel-based nature of this assay makes quantification less accurate, but it has the advantage of being able to identify later modifications to the protein, for example proteolysis or ubiquitination, from changes in size.
Quantification of protein and mRNA permits a correlation of the two levels. The question of how well protein levels correlate with their corresponding transcript levels is highly debated and depends on multiple factors. Regulation on each step of gene expression can impact the correlation, as shown for regulation of translation or protein stability. Post-translational factors, such as protein transport in highly polar cells, can influence the measured mRNA-protein correlation as well.
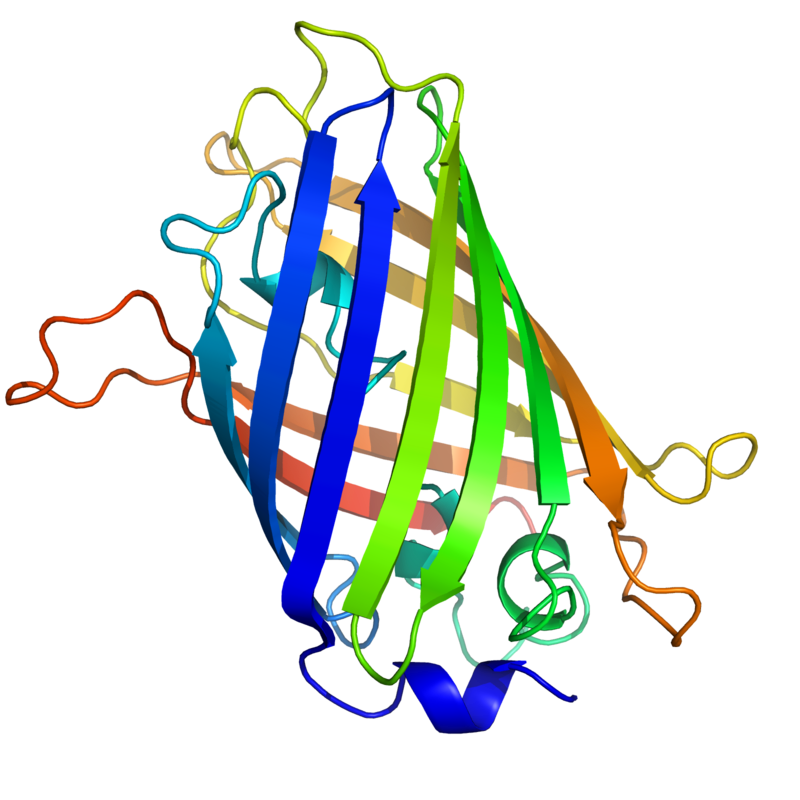
The three-dimensional structure of green fluorescent protein. The residues in the centre of the "barrel" are responsible for production of green light after exposing to higher energetic blue light. From PDB: 1EMA.
Analysis of expression is not limited to quantification; localisation can also be determined. mRNA can be detected with a suitably labelled complementary mRNA strand and protein can be detected via labelled antibodies. The probed sample is then observed by microscopy to identify where the mRNA or protein is.
By replacing the gene with a new version fused to a green fluorescent protein (or similar) marker, expression may be directly quantified in live cells. This is done by imaging using a fluorescence microscope. It is very difficult to clone a GFP-fused protein into its native location in the genome without affecting expression levels so this method often cannot be used to measure endogenous gene expression. It is, however, widely used to measure the expression of a gene artificially introduced into the cell, for example via an expression vector. It is important to note that by fusing a target protein to a fluorescent reporter the protein's behavior, including its cellular localization and expression level, can be significantly changed.
The enzyme-linked immunosorbent assay works by using antibodies immobilised on a microtiter plate to capture proteins of interest from samples added to the well. Using a detection antibody conjugated to an enzyme or fluorophore the quantity of bound protein can be accurately measured by fluorometric or colourimetric detection. The detection process is very similar to that of a Western blot, but by avoiding the gel steps more accurate quantification can be achieved.
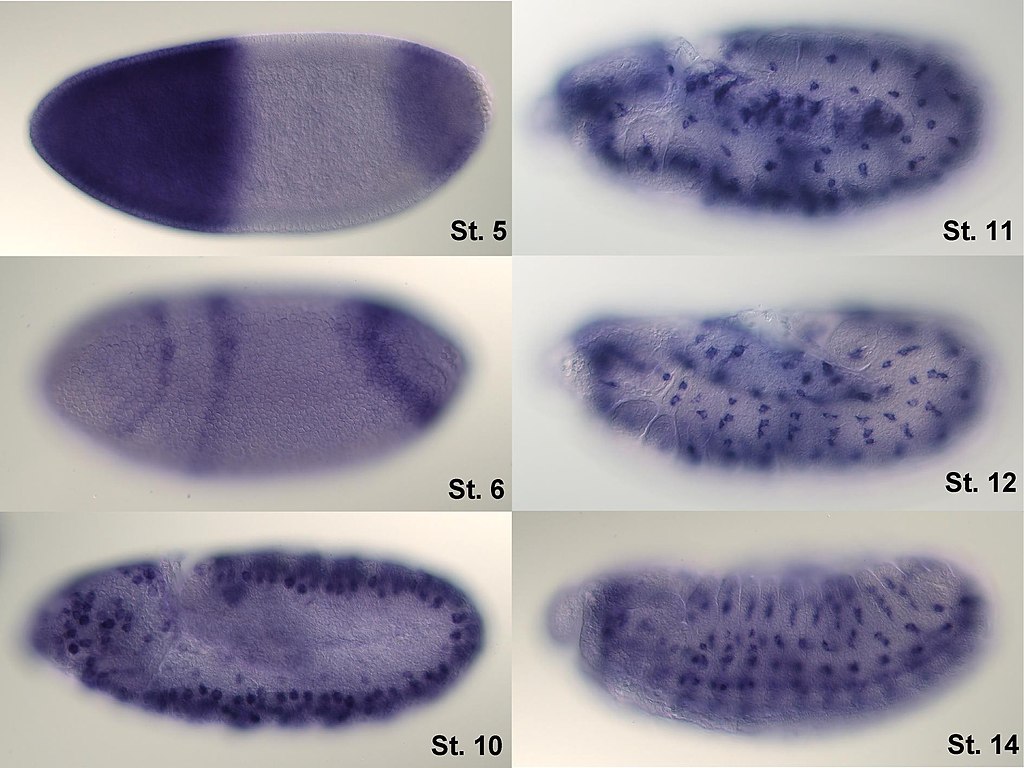
In situ-hybridization of Drosophilaembryos at different developmental stages for the mRNA responsible for the expression of hunchback. High intensity of blue color marks places with high hunchback mRNA quantity.
An expression system is a system specifically designed for the production of a gene product of choice. This is normally a protein although may also be RNA, such as tRNA or a ribozyme. An expression system consists of a gene, normally encoded by DNA, and the molecular machinery required to transcribe the DNA into mRNA and translate the mRNA into protein using the reagents provided. In the broadest sense this includes every living cell but the term is more normally used to refer to expression as a laboratory tool. An expression system is therefore often artificial in some manner. Expression systems are, however, a fundamentally natural process. Viruses are an excellent example where they replicate by using the host cell as an expression system for the viral proteins and genome.
In addition to these biological tools, certain naturally observed configurations of DNA (genes, promoters, enhancers, repressors) and the associated machinery itself are referred to as an expression system. This term is normally used in the case where a gene or set of genes is switched on under well defined conditions, for example, the simple repressor switch expression system in Lambda phage and the lac operator system in bacteria. Several natural expression systems are directly used or modified and used for artificial expression systems such as the Tet-on and Tet-off expression system.
Genes have sometimes been regarded as nodes in a network, with inputs being proteins such as transcription factors, and outputs being the level of gene expression. The node itself performs a function, and the operation of these functions have been interpreted as performing a kind of information processing within cells and determines cellular behavior.
Gene networks can also be constructed without formulating an explicit causal model. This is often the case when assembling networks from large expression data sets. Covariation and correlation of expression is computed across a large sample of cases and measurements (often transcriptome or proteome data). The source of variation can be either experimental or natural (observational). There are several ways to construct gene expression networks, but one common approach is to compute a matrix of all pair-wise correlations of expression across conditions, time points, or individuals and convert the matrix (after thresholding at some cut-off value) into a graphical representation in which nodes represent genes, transcripts, or proteins and edges connecting these nodes represent the strength of association.
The following experimental techniques are used to measure gene expression and are listed in roughly chronological order, starting with the older, more established technologies. They are divided into two groups based on their degree of multiplexity.
Paul Andersen explains how genes are regulated in both prokaryotes and eukaryotes. He begins with a description of the lac and trp operon and how they are used by bacteria in both positive and negative response. He also explains the importance of transcription factors in eukaryotic gene expression.
📹 DNA Gene Regulation and the Order of the Operon / Amobea Sisters (VİDEO)
📹 DNA Gene Regulation and the Order of the Operon / Amobea Sisters (LINK)
Explore gene expression with the Amoeba Sisters, including the fascinating Lac Operon found in bacteria! Learn how genes can be turned "on" and "off" and why this is essential for cellular function.
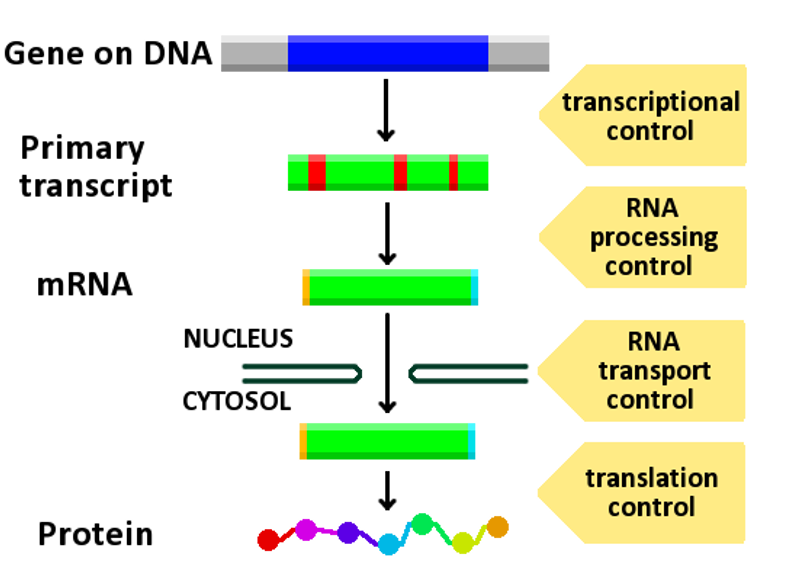
Diagram showing at which stages in the DNA-mRNA-protein pathway expression can be controlled.
Regulation of gene expression, or gene regulation, includes a wide range of mechanisms that are used by cells to increase or decrease the production of specific gene products (protein or RNA). Sophisticated programs of gene expression are widely observed in biology, for example to trigger developmental pathways, respond to environmental stimuli, or adapt to new food sources. Virtually any step of gene expression can be modulated, from transcriptional initiation, to RNA processing, and to the post-translational modification of a protein. Often, one gene regulator controls another, and so on, in a gene regulatory network.
Gene regulation is essential for viruses,prokaryotes and eukaryotes as it increases the versatility and adaptability of an organism by allowing the cell to express protein when needed. Although as early as 1951, Barbara McClintock showed interaction between two genetic loci, Activator (Ac) and Dissociator (Ds), in the color formation of maize seeds, the first discovery of a gene regulation system is widely considered to be the identification in 1961 of the lac operon, discovered by François Jacob and Jacques Monod, in which some enzymes involved in lactose metabolism are expressed by E. coli only in the presence of lactose and absence of glucose.
In multicellular organisms, gene regulation drives cellular differentiation and morphogenesis in the embryo, leading to the creation of different cell types that possess different gene expression profiles from the same genome sequence. Although this does not explain how gene regulation originated, evolutionary biologists include it as a partial explanation of how evolution works at a molecular level, and it is central to the science of evolutionary developmental biology ("evo-devo").
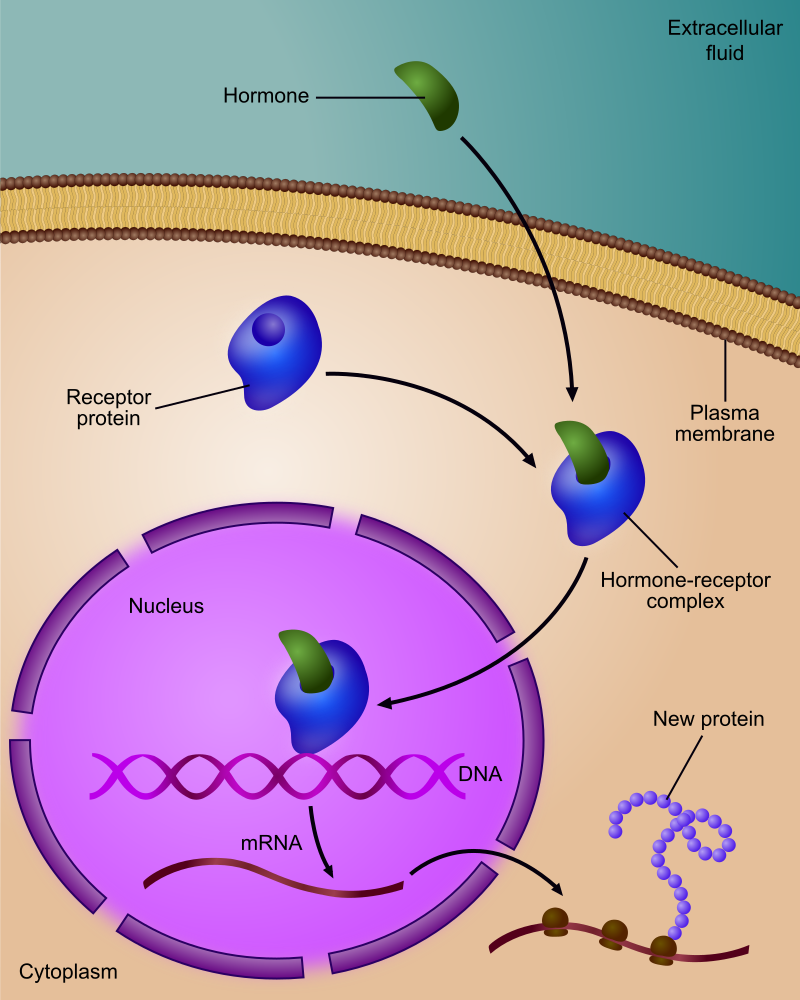
Regulation of gene expression by a hormone receptor.
Any step of gene expression may be modulated, from the DNA-RNA transcription step to post-translational modification of a protein. The following is a list of stages where gene expression is regulated, the most extensively utilised point is Transcription Initiation:
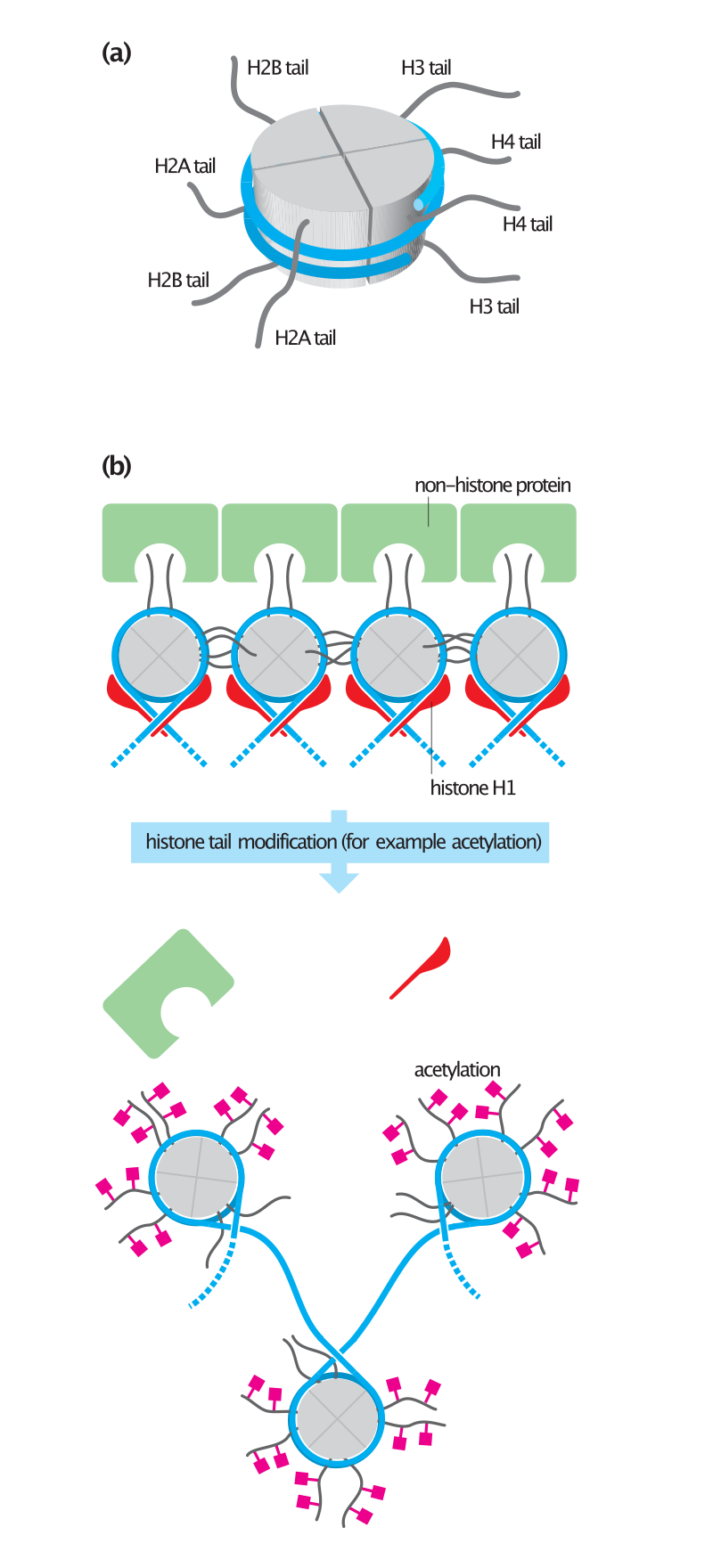
Histone tails and their function in chromatin formation.
In eukaryotes, the accessibility of large regions of DNA can depend on its chromatin structure, which can be altered as a result of histone modifications directed by DNA methylation,ncRNA, or DNA-binding protein. Hence these modifications may up or down regulate the expression of a gene. Some of these modifications that regulate gene expression are inheritable and are referred to as epigenetic regulation.
Transcription of DNA is dictated by its structure. In general, the density of its packing is indicative of the frequency of transcription. Octameric protein complexes called nucleosomes are responsible for the amount of supercoiling of DNA, and these complexes can be temporarily modified by processes such as phosphorylation or more permanently modified by processes such as methylation. Such modifications are considered to be responsible for more or less permanent changes in gene expression levels.
Methylation of DNA is a common method of gene silencing. DNA is typically methylated by methyltransferase enzymes on cytosine nucleotides in a CpG dinucleotide sequence (also called "CpG islands" when densely clustered). Analysis of the pattern of methylation in a given region of DNA (which can be a promoter) can be achieved through a method called bisulfite mapping. Methylated cytosine residues are unchanged by the treatment, whereas unmethylated ones are changed to uracil. The differences are analyzed by DNA sequencing or by methods developed to quantify SNPs, such as Pyrosequencing (Biotage) or MassArray (Sequenom), measuring the relative amounts of C/T at the CG dinucleotide. Abnormal methylation patterns are thought to be involved in oncogenesis.
Histone acetylation is also an important process in transcription. Histone acetyltransferase enzymes (HATs) such as CREB-binding protein also dissociate the DNA from the histone complex, allowing transcription to proceed. Often, DNA methylation and histone deacetylation work together in gene silencing. The combination of the two seems to be a signal for DNA to be packed more densely, lowering gene expression.
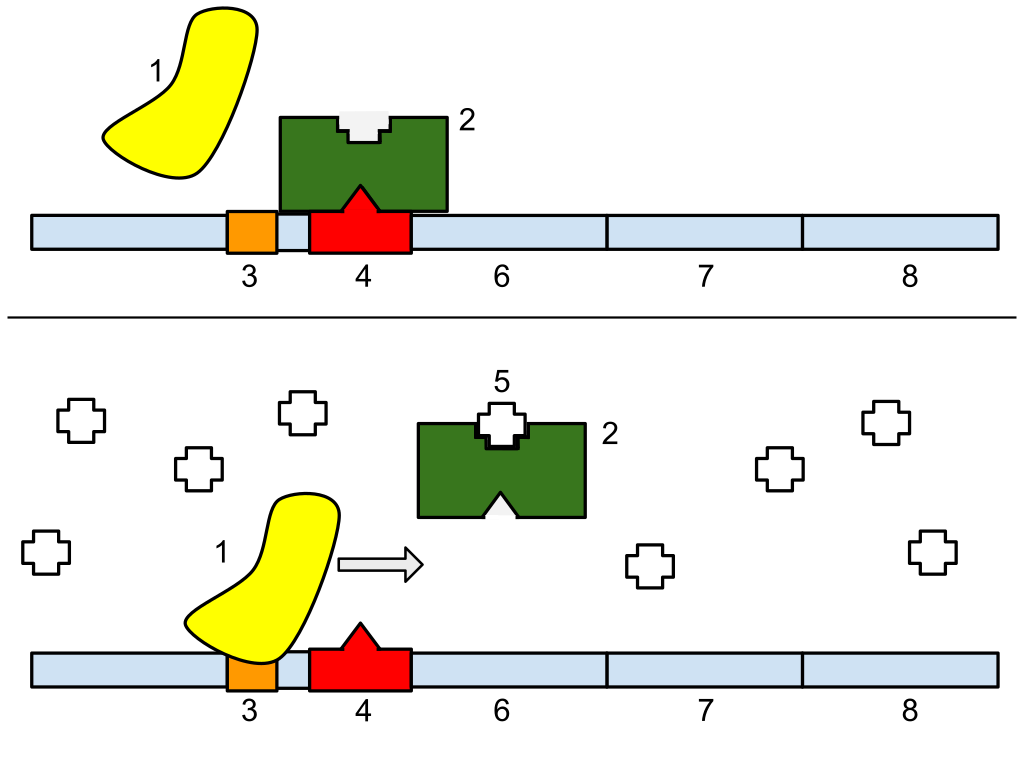
1: RNA Polymerase, 2: Repressor, 3: Promoter, 4: Operator, 5: Lactose, 6: lacZ, 7: lacY, 8: lacA. Top: The gene is essentially turned off. There is no lactose to inhibit the repressor, so the repressor binds to the operator, which obstructs the RNA polymerase from binding to the promoter and making lactase. Bottom: The gene is turned on. Lactose is inhibiting the repressor, allowing the RNA polymerase to bind with the promoter, and express the genes, which synthesize lactase. Eventually, the lactase will digest all of the lactose, until there is none to bind to the repressor. The repressor will then bind to the operator, stopping the manufacture of lactase.
Regulation of transcription thus controls when transcription occurs and how much RNA is created. Transcription of a gene by RNA polymerase can be regulated by several mechanisms. Specificity factors alter the specificity of RNA polymerase for a given promoter or set of promoters, making it more or less likely to bind to them (i.e., sigma factors used in prokaryotic transcription).Repressors bind to the Operator, coding sequences on the DNA strand that are close to or overlapping the promoter region, impeding RNA polymerase's progress along the strand, thus impeding the expression of the gene. The image to the right demonstrates regulation by a repressor in the lac operon. General transcription factors position RNA polymerase at the start of a protein-coding sequence and then release the polymerase to transcribe the mRNA. Activators enhance the interaction between RNA polymerase and a particular promoter, encouraging the expression of the gene. Activators do this by increasing the attraction of RNA polymerase for the promoter, through interactions with subunits of the RNA polymerase or indirectly by changing the structure of the DNA. Enhancers are sites on the DNA helix that are bound by activators in order to loop the DNA bringing a specific promoter to the initiation complex. Enhancers are much more common in eukaryotes than prokaryotes, where only a few examples exist (to date). Silencers are regions of DNA sequences that, when bound by particular transcription factors, can silence expression of the gene.
In vertebrates, the majority of gene promoters contain a CpG island with numerous CpG sites. When many of a gene's promoter CpG sites are methylated the gene becomes silenced. Colorectal cancers typically have 3 to 6 driver mutations and 33 to 66 hitchhiker or passenger mutations. However, transcriptional silencing may be of more importance than mutation in causing progression to cancer. For example, in colorectal cancers about 600 to 800 genes are transcriptionally silenced by CpG island methylation (see regulation of transcription in cancer). Transcriptional repression in cancer can also occur by other epigenetic mechanisms, such as altered expression of microRNAs. In breast cancer, transcriptional repression of BRCA1 may occur more frequently by over-expressed microRNA-182 than by hypermethylation of the BRCA1 promoter (see Low expression of BRCA1 in breast and ovarian cancers).
One of the cardinal features of addiction is its persistence. The persistent behavioral changes appear to be due to long-lasting changes, resulting from epigenetic alterations affecting gene expression, within particular regions of the brain. Drugs of abuse cause three types of epigenetic alteration in the brain. These are (1) histone acetylations and histone methylations, (2) DNA methylation at CpG sites, and (3) epigenetic downregulation or upregulation of microRNAs. (See Epigenetics of cocaine addiction for some details.)
Chronic nicotine intake in mice alters brain cell epigenetic control of gene expression through acetylation of histones. This increases expression in the brain of the protein FosB, important in addiction. Cigarette addiction was also studied in about 16,000 humans, including never smokers, current smokers, and those who had quit smoking for up to 30 years. In blood cells, more than 18,000 CpG sites (of the roughly 450,000 analyzed CpG sites in the genome) had frequently altered methylation among current smokers. These CpG sites occurred in over 7,000 genes, or roughly a third of known human genes. The majority of the differentially methylated CpG sites returned to the level of never-smokers within five years of smoking cessation. However, 2,568 CpGs among 942 genes remained differentially methylated in former versus never smokers. Such remaining epigenetic changes can be viewed as “molecular scars” that may affect gene expression.
In rodent models, drugs of abuse, including cocaine, methampheamine, alcohol and tobacco smoke products, all cause DNA damage in the brain. During repair of DNA damages some individual repair events can alter the methylation of DNA and/or the acetylations or methylations of histones at the sites of damage, and thus can contribute to leaving an epigenetic scar on chromatin.
Such epigenetic scars likely contribute to the persistent epigenetic changes found in addiction.
Regulation of transcription in learning and memory
Regulation of transcription in learning and memory
Regulation of transcription in learning and memory (W)
DNA methylation is the addition of a methyl group to the DNA that happens at cytosine. The image shows a cytosine single ring base and a methyl group added on to the 5 carbon. In mammals, DNA methylation occurs almost exclusively at a cytosine that is followed by a guanine.
In mammals, methylation of cytosine (see Figure) in DNA is a major regulatory mediator. Methylated cytosines primarily occur in dinucleotide sequences where cytosine is followed by a guanine, a CpG site. The total number of CpG sites in the human genome is approximately 28 million. and generally about 70% of all CpG sites have a methylated cytosine.
In a rat, a painful learning experience, contextual fear conditioning, can result in a life-long fearful memory after a single training event. Cytosine methylation is altered in the promoter regions of about 9.17% of all genes in the hippocampus neuron DNA of a rat that has been subjected to a brief fear conditioning experience. The hippocampus is where new memories are initially stored.
Methylation of CpGs in a promoter region of a gene represses transcription while methylation of CpGs in the body of a gene increases expression. TET enzymes play a central role in demethylation of methylated cytosines. Demethylation of CpGs in a gene promoter by TET enzyme activity increases transcription of the gene.
The identified areas of the human brain are involved in memory formation.
When contextual fear conditioning is applied to a rat, more than 5,000 differentially methylated regions (DMRs) (of 500 nucleotides each) occur in the rat hippocampus neural genome both one hour and 24 hours after the conditioning in the hippocampus. This causes about 500 genes to be up-regulated (often due to demethylation of CpG sites in a promoter region) and about 1,000 genes to be down-regulated (often due to newly formed 5-methylcytosine at CpG sites in a promoter region). The pattern of induced and repressed genes within neurons appears to provide a molecular basis for forming the first transient memory of this training event in the hippocampus of the rat brain.
After the DNA is transcribed and mRNA is formed, there must be some sort of regulation on how much the mRNA is translated into proteins. Cells do this by modulating the capping, splicing, addition of a Poly(A) Tail, the sequence-specific nuclear export rates, and, in several contexts, sequestration of the RNA transcript. These processes occur in eukaryotes but not in prokaryotes. This modulation is a result of a protein or transcript that, in turn, is regulated and may have an affinity for certain sequences.
Three prime untranslated regions and microRNAs
Three prime untranslated regions and microRNAs
Three prime untranslated regions and microRNAs (W)
Three prime untranslated regions (3'-UTRs) of messenger RNAs (mRNAs) often contain regulatory sequences that post-transcriptionally influence gene expression.Such 3'-UTRs often contain both binding sites for microRNAs (miRNAs) as well as for regulatory proteins. By binding to specific sites within the 3'-UTR, miRNAs can decrease gene expression of various mRNAs by either inhibiting translation or directly causing degradation of the transcript. The 3'-UTR also may have silencer regions that bind repressor proteins that inhibit the expression of a mRNA.
The 3'-UTR often contains miRNA response elements (MREs). MREs are sequences to which miRNAs bind. These are prevalent motifs within 3'-UTRs. Among all regulatory motifs within the 3'-UTRs (e.g. including silencer regions), MREs make up about half of the motifs.
As of 2014, the miRBase web site, an archive of miRNA sequences and annotations, listed 28,645 entries in 233 biologic species. Of these, 1,881 miRNAs were in annotated human miRNA loci. miRNAs were predicted to have an average of about four hundred target mRNAs (affecting expression of several hundred genes). Freidman et al. estimate that >45,000 miRNA target sites within human mRNA 3'-UTRs are conserved above background levels, and >60% of human protein-coding genes have been under selective pressure to maintain pairing to miRNAs.
Direct experiments show that a single miRNA can reduce the stability of hundreds of unique mRNAs. Other experiments show that a single miRNA may repress the production of hundreds of proteins, but that this repression often is relatively mild (less than 2-fold).
The effects of miRNA dysregulation of gene expression seem to be important in cancer. For instance, in gastrointestinal cancers, a 2015 paper identified nine miRNAs as epigenetically altered and effective in down-regulating DNA repair enzymes.
The translation of mRNA can also be controlled by a number of mechanisms, mostly at the level of initiation. Recruitment of the small ribosomal subunit can indeed be modulated by mRNA secondary structure, antisense RNA binding, or protein binding. In both prokaryotes and eukaryotes, a large number of RNA binding proteins exist, which often are directed to their target sequence by the secondary structure of the transcript, which may change depending on certain conditions, such as temperature or presence of a ligand (aptamer). Some transcripts act as ribozymes and self-regulate their expression.
The Lac operon is an interesting example of how gene expression can be regulated.
Viruses, despite having only a few genes, possess mechanisms to regulate their gene expression, typically into an early and late phase, using collinear systems regulated by anti-terminators (lambda phage) or splicing modulators (HIV).
Gal4 is a transcriptional activator that controls the expression of GAL1, GAL7, and GAL10 (all of which code for the metabolic of galactose in yeast). The GAL4/UAS system has been used in a variety of organisms across various phyla to study gene expression.
A large number of studied regulatory systems come from developmental biology. Examples include:
The colinearity of the Hox gene cluster with their nested antero-posterior patterning
Pattern generation of the hand (digits - interdigits): the gradient of sonic hedgehog (secreted inducing factor) from the zone of polarizing activity in the limb, which creates a gradient of active Gli3, which activates Gremlin, which inhibits BMPs also secreted in the limb, results in the formation of an alternating pattern of activity as a result of this reaction-diffusion system.
Somitogenesis is the creation of segments (somites) from a uniform tissue (Pre-somitic Mesoderm). They are formed sequentially from anterior to posterior. This is achieved in amniotes possibly by means of two opposing gradients, Retinoic acid in the anterior (wavefront) and Wnt and Fgf in the posterior, coupled to an oscillating pattern (segmentation clock) composed of FGF + Notch and Wnt in antiphase.
Sex determination in the soma of a Drosophila requires the sensing of the ratio of autosomal genes to sex chromosome-encoded genes, which results in the production of sexless splicing factor in females, resulting in the female isoform of doublesex.
Up-regulation is a process that occurs within a cell triggered by a signal (originating internal or external to the cell), which results in increased expression of one or more genes and as a result the protein(s) encoded by those genes. Conversely, down-regulation is a process resulting in decreased gene and corresponding protein expression.
Up-regulation occurs, for example, when a cell is deficient in some kind of receptor. In this case, more receptor protein is synthesized and transported to the membrane of the cell and, thus, the sensitivity of the cell is brought back to normal, reestablishing homeostasis.
Down-regulation occurs, for example, when a cell is overstimulated by a neurotransmitter,hormone, or drug for a prolonged period of time, and the expression of the receptor protein is decreased in order to protect the cell (see also tachyphylaxis).
Gene Regulation can be summarized by the response of the respective system:
Inducible systems - An inducible system is off unless there is the presence of some molecule (called an inducer) that allows for gene expression. The molecule is said to "induce expression". The manner by which this happens is dependent on the control mechanisms as well as differences between prokaryotic and eukaryotic cells.
Repressible systems - A repressible system is on except in the presence of some molecule (called a corepressor) that suppresses gene expression. The molecule is said to "repress expression". The manner by which this happens is dependent on the control mechanisms as well as differences between prokaryotic and eukaryotic cells.
The GAL4/UAS system is an example of both an inducible and repressible system. Gal4 binds an upstream activation sequence (UAS) to activate the transcription of the GAL1/GAL7/GAL10 cassette. On the other hand, a MIG1 response to the presence of glucose can inhibit GAL4 and therefore stop the expression of the GAL1/GAL7/GAL10 cassette.
In general, most experiments investigating differential expression used whole cell extracts of RNA, called steady-state levels, to determine which genes changed and by how much. These are, however, not informative of where the regulation has occurred and may mask conflicting regulatory processes (see post-transcriptional regulation), but it is still the most commonly analysed (quantitative PCR and DNA microarray).
When studying gene expression, there are several methods to look at the various stages. In eukaryotes these include:
Due to post-transcriptional regulation, transcription rates and total RNA levels differ significantly. To measure the transcription rates nuclear run-on assays can be done and newer high-throughput methods are being developed, using thiol labelling instead of radioactivity.
Only 5% of the RNA polymerised in the nucleus exits, and not only introns, abortive products, and non-sense transcripts are degradated. Therefore, the differences in nuclear and cytoplasmic levels can be see by separating the two fractions by gentle lysis.
Alternative splicing can be analysed with a splicing array or with a tiling array (see DNA microarray).
All in vivo RNA is complexed as RNPs. The quantity of transcripts bound to specific protein can be also analysed by RIP-Chip. For example, DCP2 will give an indication of sequestered protein; ribosome-bound gives and indication of transcripts active in transcription (although a more dated method, called polysome fractionation, is still popular in some labs)
RNA and protein degradation rates are measured by means of transcription inhibitors (actinomycin D or α-amanitin) or translation inhibitors (Cycloheximide), respectively.
The movie of "The Central dogma" is made by RIKEN Yokohama institute Omics Science Center(RIKEN OSC) It is the latest version.
We tried to illustrate how molecular machines interact each other in the central dogma by giving "Japanese robot-anime" style representation to the molecules. By using this approach, people (especially kids) can easily distinguish between those molecules and understand how they function in our body.
The 'Central Dogma' of molecular biology is that 'DNA makes RNA makes protein'. This animation shows how molecular machines transcribe the genes in the DNA of every cell into portable RNA messages, how those messenger RNA are modified and exported from the nucleus, and finally how the RNA code is read to build proteins.
The video was made by RIKEN Omics Science Center (RIKEN OSC http://www.osc.riken.jp/english/ ) for the exhibition titled 'Beyond DNA' held at National Science Museum of Japan. RIKEN OSC has published in Nature Genetics on the regulation of RNA expression in human cancer cells: http://www.nature.com/ng/journal/v41/...
The central dogma of molecular biology is an explanation of the flow of genetic information within a biological system. it is often stated as “DNA makes RNA, and RNA makes protein,” although this is not its original meaning. It was first stated by Francis Crick in 1957, then published in 1958:
“The Central Dogma. This states that once "information" has passed into protein it cannot get out again. In more detail, the transfer of information from nucleic acid to nucleic acid, or from nucleic acid to protein may be possible, but transfer from protein to protein, or from protein to nucleic acid is impossible. Information means here the precise determination of sequence, either of bases in the nucleic acid or of amino acid residues in the protein.”
— Francis Crick, 1958
and re-stated in a Nature paper published in 1970:
Information flow in biological systems.
“The central dogma of molecular biology deals with the detailed residue-by-residue transfer of sequential information. It states that such information cannot be transferred back from protein to either protein or nucleic acid.”
— Francis Crick
A second version of the central dogma is popular but incorrect. This is the simplistic DNA → RNA → protein pathway published by James Watson in the first edition of The Molecular Biology of the Gene (1965). Watson's version differs from Crick's because Watson describes a two-step (DNA → RNA and RNA → protein) process as the central dogma. While the dogma, as originally stated by Crick, remains valid today, Watson's version does not.
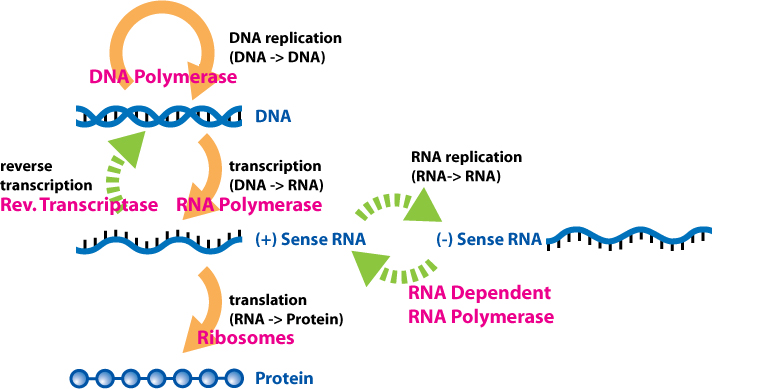
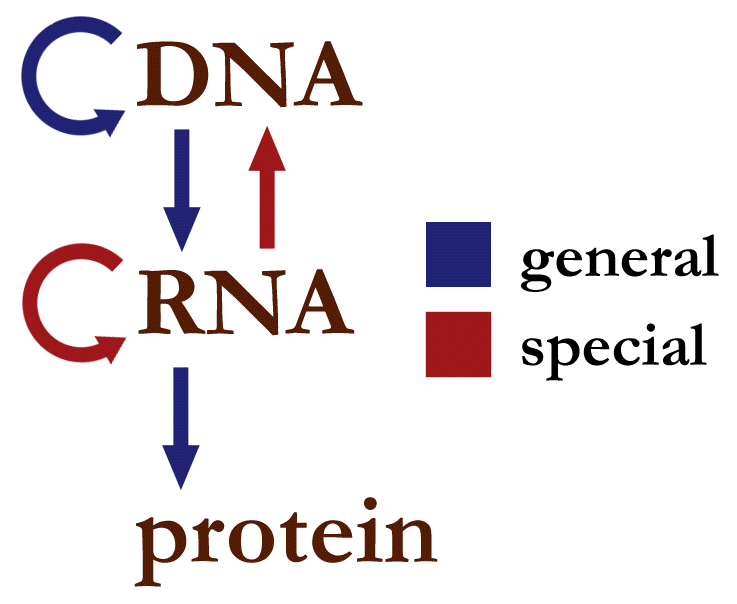
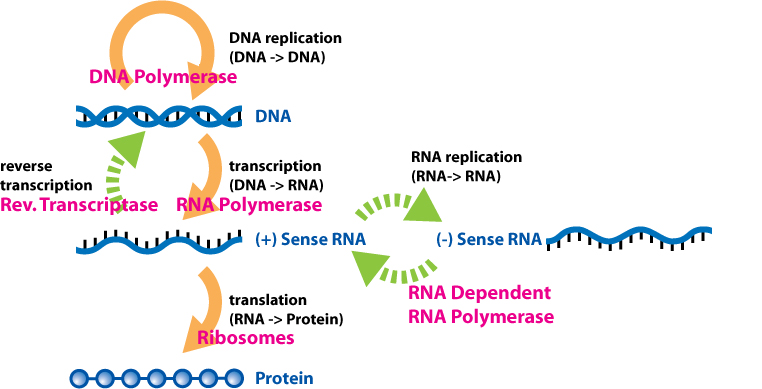
The dogma is a framework for understanding the transfer of sequenceinformation between information-carrying biopolymers, in the most common or general case, in living organisms. There are 3 major classes of such biopolymers: DNA and RNA (both nucleic acids), and protein. There are 3 × 3 = 9 conceivable direct transfers of information that can occur between these. The dogma classes these into 3 groups of 3: three general transfers (believed to occur normally in most cells), three special transfers (known to occur, but only under specific conditions in case of some viruses or in a laboratory), and three unknown transfers (believed never to occur). The general transfers describe the normal flow of biological information: DNA can be copied to DNA (DNA replication), DNA information can be copied into mRNA (transcription), and proteins can be synthesized using the information in mRNA as a template (translation). The special transfers describe: RNA being copied from RNA (RNA replication), DNA being synthesised using an RNA template (reverse transcription), and proteins being synthesised directly from a DNA template without the use of mRNA. The unknown transfers describe: a protein being copied from a protein, synthesis of RNA using the primary structure of a protein as a template, and DNA synthesis using the primary structure of a protein as a template - these are not thought to naturally occur.
The biopolymers that comprise DNA, RNA and (poly)peptides are linear polymers (i.e.: each monomer is connected to at most two other monomers). The sequence of their monomers effectively encodes information. The transfers of information described by the central dogma ideally are faithful, deterministic transfers, wherein one biopolymer's sequence is used as a template for the construction of another biopolymer with a sequence that is entirely dependent on the original biopolymer's sequence.
General transfers of biological sequential information
General transfers of biological sequential information
General transfers of biological sequential information (W)
Overview of the central dogma of molecular biology. Original work by Mike Jones for wikipedia.
Table of the three classes of information transfer suggested by the dogma
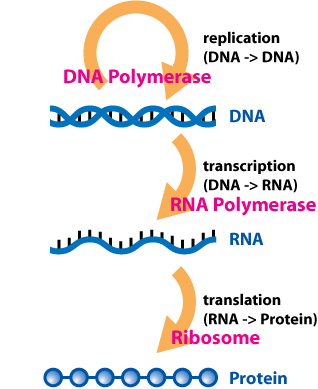
In the sense that DNA replication must occur if genetic material is to be provided for the progeny of any cell, whether somatic or reproductive, the copying from DNA to DNA arguably is the fundamental step in the central dogma. A complex group of proteins called the replisome performs the replication of the information from the parent strand to the complementary daughter strand.
SSB protein that binds open the double-stranded DNA to prevent it from reassociating
RNA primase that adds a complementary RNA primer to each template strand as a starting point for replication
DNA polymerase III that reads the existing template chain from its 3' end to its 5' end and adds new complementary nucleotides from the 5' end to the 3' end of the daughter chain
DNA polymerase I that removes the RNA primers and replaces them with DNA
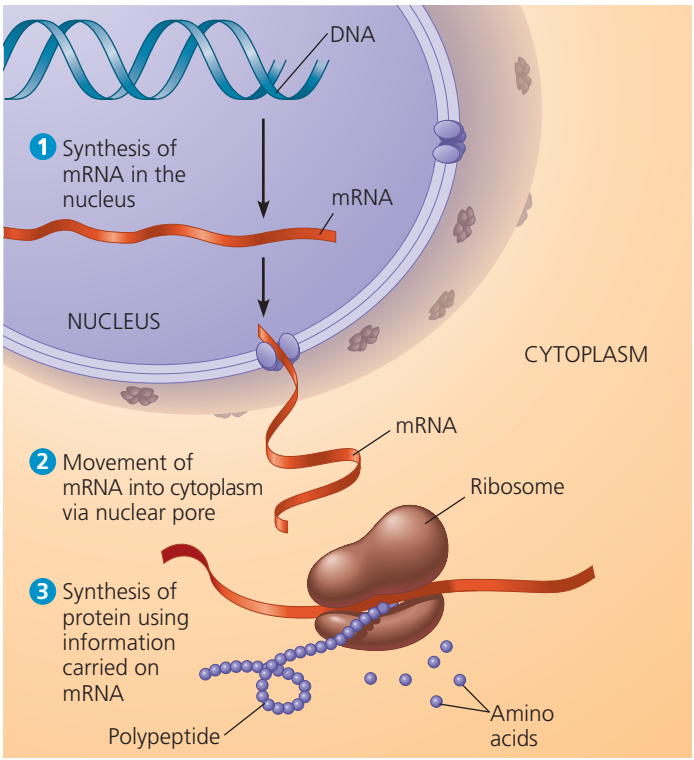
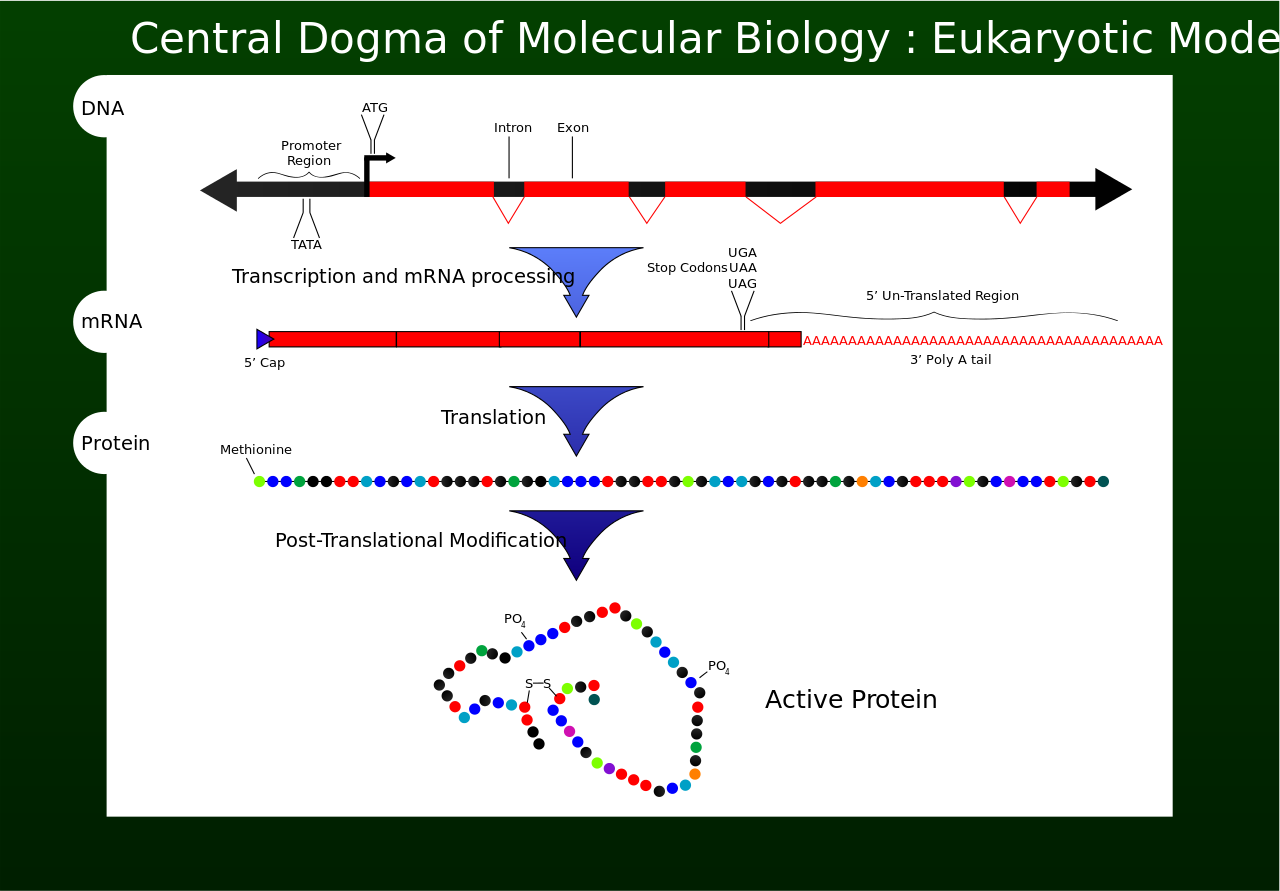
Transcription is the process by which the information contained in a section of DNA is replicated in the form of a newly assembled piece of messenger RNA (mRNA). Enzymes facilitating the process include RNA polymerase and transcription factors. In eukaryotic cells the primary transcript is pre-mRNA. Pre-mRNA must be processed for translation to proceed. Processing includes the addition of a 5' cap and a poly-A tail to the pre-mRNA chain, followed by splicing.Alternative splicing occurs when appropriate, increasing the diversity of the proteins that any single mRNA can produce. The product of the entire transcription process (that began with the production of the pre-mRNA chain) is a mature mRNA chain.
The mature mRNA finds its way to a ribosome, where it gets translated. In prokaryotic cells, which have no nuclear compartment, the processes of transcription and translation may be linked together without clear separation. In eukaryotic cells, the site of transcription (the cell nucleus) is usually separated from the site of translation (the cytoplasm), so the mRNA must be transported out of the nucleus into the cytoplasm, where it can be bound by ribosomes. The ribosome reads the mRNA triplet codons, usually beginning with an AUG (adenine−uracil−guanine), or initiator methionine codon downstream of the ribosome binding site. Complexes of initiation factors and elongation factors bring aminoacylatedtransfer RNAs (tRNAs) into the ribosome-mRNA complex, matching the codon in the mRNA to the anti-codon on the tRNA. Each tRNA bears the appropriate amino acid residue to add to the polypeptide chain being synthesised. As the amino acids get linked into the growing peptide chain, the chain begins folding into the correct conformation. Translation ends with a stop codon which may be a UAA, UGA, or UAG triplet.
The mRNA does not contain all the information for specifying the nature of the mature protein. The nascent polypeptide chain released from the ribosome commonly requires additional processing before the final product emerges. For one thing, the correct folding process is complex and vitally important. For most proteins it requires other chaperone proteins to control the form of the product. Some proteins then excise internal segments from their own peptide chains, splicing the free ends that border the gap; in such processes the inside "discarded" sections are called inteins. Other proteins must be split into multiple sections without splicing. Some polypeptide chains need to be cross-linked, and others must be attached to cofactors such as haem (heme) before they become functional.
Reverse transcription is the transfer of information from RNA to DNA (the reverse of normal transcription). This is known to occur in the case of retroviruses, such as HIV, as well as in eukaryotes, in the case of retrotransposons and telomere synthesis. It is the process by which genetic information from RNA gets transcribed into new DNA.
Unusual flows of information highlighted in green.
RNA replication is the copying of one RNA to another. Many viruses replicate this way. The enzymes that copy RNA to new RNA, called RNA-dependent RNA polymerases, are also found in many eukaryotes where they are involved in RNA silencing.
RNA editing, in which an RNA sequence is altered by a complex of proteins and a "guide RNA", could also be seen as an RNA-to-RNA transfer.
Direct translation from DNA to protein has been demonstrated in a cell-free system (i.e. in a test tube), using extracts from E. coli that contained ribosomes, but not intact cells. These cell fragments could synthesize proteins from single-stranded DNA templates isolated from other organisms (e,g., mouse or toad), and neomycin was found to enhance this effect. However, it was unclear whether this mechanism of translation corresponded specifically to the genetic code.
Transfers of information not explicitly covered in the theory
Transfers of information not explicitly covered in the theory
Transfers of information not explicitly covered in the theory (W)
After protein amino acid sequences have been translated from nucleic acid chains, they can be edited by appropriate enzymes. Although this is a form of protein affecting protein sequence, not explicitly covered by the central dogma, there are not many clear examples where the associated concepts of the two fields have much to do with each other.
An intein is a "parasitic" segment of a protein that is able to excise itself from the chain of amino acids as they emerge from the ribosome and rejoin the remaining portions with a peptide bond in such a manner that the main protein "backbone" does not fall apart. This is a case of a protein changing its own primary sequence from the sequence originally encoded by the DNA of a gene. Additionally, most inteins contain a homing endonuclease or HEG domain which is capable of finding a copy of the parent gene that does not include the intein nucleotide sequence. On contact with the intein-free copy, the HEG domain initiates the DNA double-stranded break repair mechanism. This process causes the intein sequence to be copied from the original source gene to the intein-free gene. This is an example of protein directly editing DNA sequence, as well as increasing the sequence's heritable propagation.
Variation in methylation states of DNA can alter gene expression levels significantly. Methylation variation usually occurs through the action of DNA methylases. When the change is heritable, it is considered epigenetic. When the change in information status is not heritable, it would be a somatic epitype. The effective information content has been changed by means of the actions of a protein or proteins on DNA, but the primary DNA sequence is not altered.
Prions are proteins of particular amino acid sequences in particular conformations. They propagate themselves in host cells by making conformational changes in other molecules of protein with the same amino acid sequence, but with a different conformation that is functionally important or detrimental to the organism. Once the protein has been transconformed to the prion folding it changes function. In turn it can convey information into new cells and reconfigure more functional molecules of that sequence into the alternate prion form. In some types of prion in fungi this change is continuous and direct; the information flow is Protein → Protein.
Some scientists such as Alain E. Bussard and Eugene Koonin have argued that prion-mediated inheritance violates the central dogma of molecular biology. However, Rosalind Ridley in Molecular Pathology of the Prions (2001) has written that "The prion hypothesis is not heretical to the central dogma of molecular biology—that the information necessary to manufacture proteins is encoded in the nucleotide sequence of nucleic acid—because it does not claim that proteins replicate. Rather, it claims that there is a source of information within protein molecules that contributes to their biological function, and that this information can be passed on to other molecules."
Natural genetic engineering
James A. Shapiro argues that a superset of these examples should be classified as natural genetic engineering and are sufficient to falsify the central dogma. While Shapiro has received a respectful hearing for his view, his critics have not been convinced that his reading of the central dogma is in line with what Crick intended.
"I called this idea the central dogma, for two reasons, I suspect. I had already used the obvious word hypothesis in the sequence hypothesis, and in addition I wanted to suggest that this new assumption was more central and more powerful. ... As it turned out, the use of the word dogma caused almost more trouble than it was worth. Many years later Jacques Monod pointed out to me that I did not appear to understand the correct use of the word dogma, which is a belief that cannot be doubted. I did apprehend this in a vague sort of way but since I thought that all religious beliefs were without foundation, I used the word the way I myself thought about it, not as most of the world does, and simply applied it to a grand hypothesis that, however plausible, had little direct experimental support."
"My mind was, that a dogma was an idea for which there was no reasonable evidence. You see?!" And Crick gave a roar of delight. "I just didn't know what dogma meant. And I could just as well have called it the 'Central Hypothesis,' or — you know. Which is what I meant to say. Dogma was just a catch phrase."
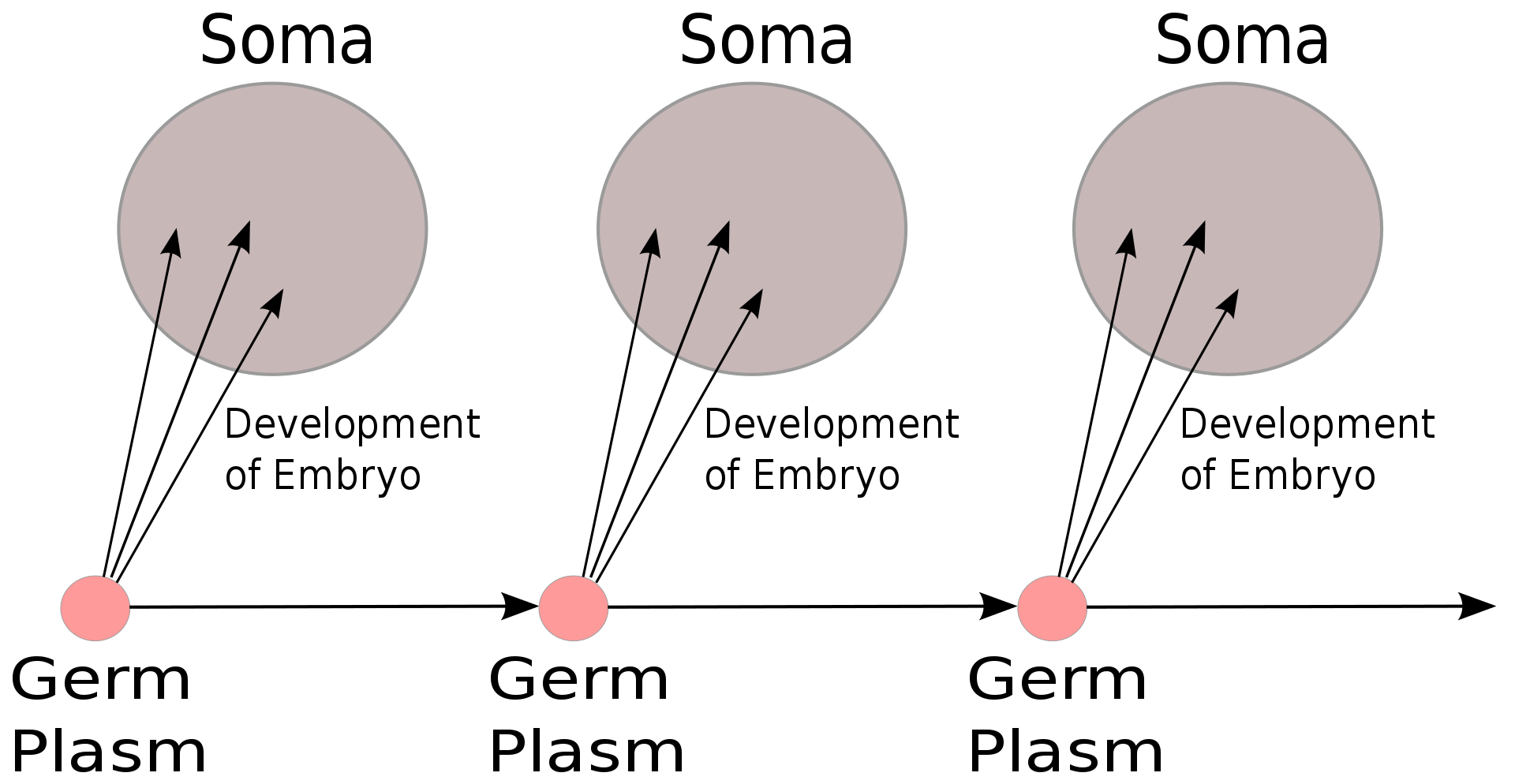
The Weismann barrier, proposed by August Weismann in 1892, distinguishes between the "immortal" germ cell lineages (the germ plasm) which produce gametes and the "disposable" somatic cells. Hereditary information moves only from germline cells to somatic cells (that is, somatic mutations are not inherited). This, before the discovery of the role or structure of DNA, does not predict the central dogma, but does anticipate its gene-centric view of life, albeit in non-molecular terms.
In August Weismann's germ plasm theory, the hereditary material, the germ plasm, is confined to the gonads. Somatic cells (of the body) develop afresh in each generation from the germ plasm. Whatever may happen to those cells does not affect the next generation.




{kind=link}
{kind=link}